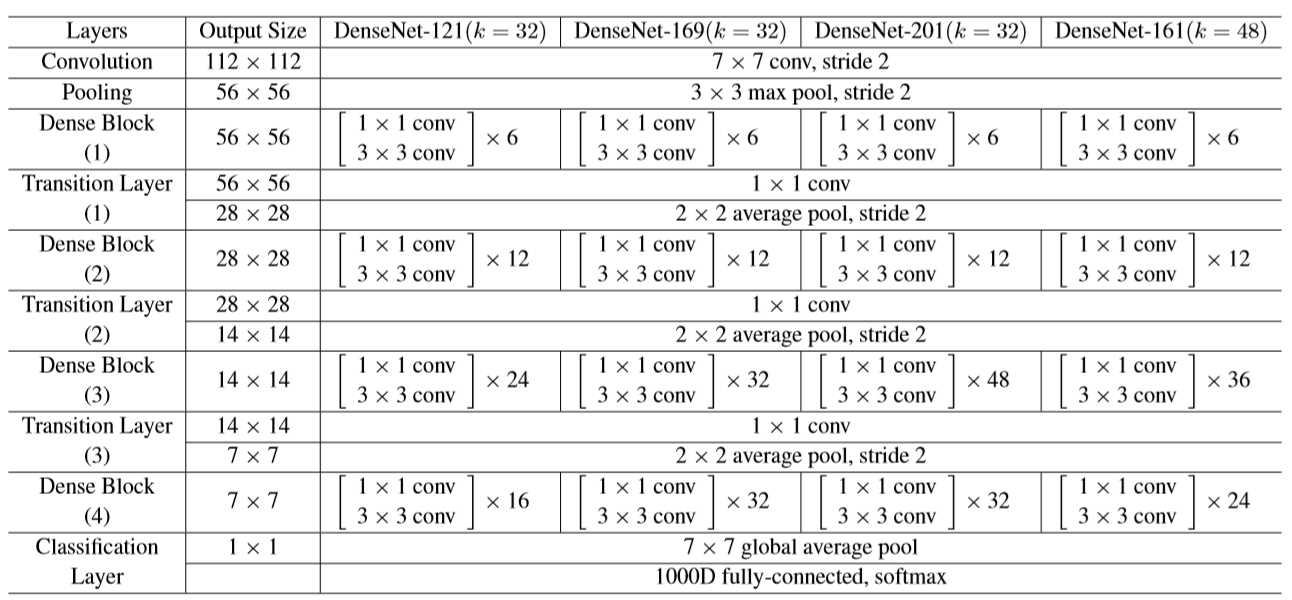
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
|
"""DenseNet, implemented in Gluon."""
import sys
import os
import mxnet as mx
import mxnet.ndarray as nd
import mxnet.gluon as gluon
import mxnet.gluon.nn as nn
import mxnet.autograd as ag
import symbol_utils
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
from config import config
def Act():
if config.net_act == 'prelu':
return nn.PReLU()
else:
return nn.Activation(config.net_act)
def _make_dense_block(num_layers, bn_size, growth_rate, dropout, stage_index):
out = nn.HybridSequential(prefix='stage%d_' % stage_index)
with out.name_scope():
for _ in range(num_layers):
out.add(_make_dense_layer(growth_rate, bn_size, dropout))
return out
def _make_dense_layer(growth_rate, bn_size, dropout):
new_features = nn.HybridSequential(prefix='')
new_features.add(nn.BatchNorm())
new_features.add(Act())
new_features.add(nn.Conv2D(bn_size * growth_rate, kernel_size=1, use_bias=False))
new_features.add(nn.BatchNorm())
new_features.add(Act())
new_features.add(nn.Conv2D(growth_rate, kernel_size=3, padding=1, use_bias=False))
if dropout:
new_features.add(nn.Dropout(dropout))
out = gluon.contrib.nn.HybridConcurrent(axis=1, prefix='')
out.add(gluon.contrib.nn.Identity())
out.add(new_features)
return out
def _make_transition(num_output_features):
out = nn.HybridSequential(prefix='')
out.add(nn.BatchNorm())
out.add(Act())
out.add(nn.Conv2D(num_output_features, kernel_size=1, use_bias=False))
out.add(nn.AvgPool2D(pool_size=2, strides=2))
return out
class DenseNet(nn.HybridBlock):
r"""Densenet-BC model from the
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_ paper.
Parameters
----------
num_init_features : int
Number of filters to learn in the first convolution layer.
growth_rate : int
Number of filters to add each layer (`k` in the paper).
block_config : list of int
List of integers for numbers of layers in each pooling block.
bn_size : int, default 4
Multiplicative factor for number of bottle neck layers.
(i.e. bn_size * k features in the bottleneck layer)
dropout : float, default 0
Rate of dropout after each dense layer.
classes : int, default 1000
Number of classification classes.
"""
def __init__(self, num_init_features, growth_rate, block_config,
bn_size=4, dropout=0, classes=1000, **kwargs):
super(DenseNet, self).__init__(**kwargs)
with self.name_scope():
self.features = nn.HybridSequential(prefix='')
self.features.add(nn.Conv2D(num_init_features, kernel_size=3,
strides=1, padding=1, use_bias=False))
self.features.add(nn.BatchNorm())
self.features.add(nn.Activation('relu'))
self.features.add(nn.MaxPool2D(pool_size=3, strides=2, padding=1))
num_features = num_init_features
for i, num_layers in enumerate(block_config):
self.features.add(_make_dense_block(num_layers, bn_size, growth_rate, dropout, i + 1))
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
self.features.add(_make_transition(num_features // 2))
num_features = num_features // 2
self.features.add(nn.BatchNorm())
self.features.add(nn.Activation('relu'))
def hybrid_forward(self, F, x):
x = self.features(x)
return x
densenet_spec = {121: (64, 32, [6, 12, 24, 16]),
161: (96, 48, [6, 12, 36, 24]),
169: (64, 32, [6, 12, 32, 32]),
201: (64, 32, [6, 12, 48, 32])}
def get_symbol():
num_layers = 121
num_init_features, growth_rate, block_config = densenet_spec[num_layers]
net = DenseNet(num_init_features, growth_rate, block_config, dropout=False)
data = mx.sym.Variable(name='data')
data = data - 127.5
data = data * 0.0078125
body = net(data)
fc1 = symbol_utils.get_fc1(body, config.emb_size, config.net_output)
return fc1
if __name__=="__main__":
fc = get_symbol()
digraph = mx.viz.plot_network(fc, title='densenet121', shape={'data': (1,3,112, 112)},node_attrs={"fixedsize": "false"})
digraph.view()
|